
简介
CTC经常使用于语音识别中,这次我们将基于RNN讲一讲它。
对语音进行识别的时候,一般需要把语音分成许多时间步,这样的话才能够有办法将其识别,比如:
_bbee_ee___
由于语音被拖长,bee这个词只能显示如上,其中还包括了空白(blank),RNN中,我们把这个词的总时间步(time step)记为T, 而对于每个时间步长,它还有一个维度就是概率分布,假设字母表共有C个字母,则这个词语的维度就是C * T。
上面的例子是我们记录下来的形式,实际真实的标签(ground truth)应该是bee,肯定小于记录形式的长度。在这里,我需要对真实标签进行扩充。对于bee,我需要如下的表示:
_b_e_e_
对于这样一个中间的表示,我需要设它的长度为S,其原来真实标签的长度为L, 故有以下关系,S = 2L + 1。
接下来我们需要做的是前向计算(forward algorithm),其中还提到了动态规划(Dynamic Programing),了解了一下,不过比较迷,还未找到之间的联系。
这里我们假设对于RNN来说:其输出结果是[R1, R2, R3, R4], 而对于真实标签的中间状态G为[blank, g1, blank, g2, blank, g3, blank]。我们知道,R1只能对应blank或者g1, 而因此对于 t = 1, 我们有概率[P[0][1], P[1][1], 0, 0, 0, 0, 0],对于t = 2, 我们有[0, (P[0][1] + P[1][1]) P[1][2], P[1][1] P[2][2], P[1][1] * P[3][2], 0, 0, 0], 以此类推。这实际上就是一种条件概率,根据前面的时间步的概率来计算下一个时间步的概率。从这一点来看,的确是借鉴了动态规划的思想就是将复杂的问题转化为一个个简单的子问题。
代码解析
其实根据前面的概率分析我们知道,输出结果对应真实标签的输出状态的概率分布是有一定规律的,从某个时刻开始某一项之前就不能再有对应项了,不然的话,输出就无法走不完全程,也就是无法对应全部真实标签,同理,在开始的时候,前几个输出项也不能对应G的后面几项。因此,我们设置start 和 end两个标准,所有对应只能在它们之间。下面是start 和 end 的计算方式。
1 | int remain = (S / 2) + repeats - (T - t) |
我们先不看repeats, S / 2是真实标签的数量, 当 t = 0 的时候,remain应该是负数,当remain>0的时候,意味着start不能待在开始,n = 1,意味着start需要到2处,n = 3,说明start需要到6处,以此类推,所以在不考虑repeats的情况下,每次start加2,而end同理。
但是我们必须考虑有repeats的情况,当真实标签中有重复比如bee的情况的时候,两个e之间的空白不能跳过,不然我们会认为只有一个e,因此start和end在遇到有重复的情况的时候,只能加一,加一这种状态必须出现两次。repeats每多一次,starts的增加就少一次,所以remai必须加上repeats以保证提前变为正数。由此,以上代码就解释的通了。
通过以上解释,数组的初始化也应该说得通了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21nt e_counter = 0;
int s_counter = 0;
s_inc[s_counter++] = 1;
int repeats = 0;
for (int i = 1; i < L; ++i) {
if (labels[i-1] == labels[i]) {
s_inc[s_counter++] = 1;
s_inc[s_counter++] = 1;
e_inc[e_counter++] = 1;
e_inc[e_counter++] = 1;
++repeats;
}
else {
s_inc[s_counter++] = 2;
e_inc[e_counter++] = 2;
}
}
e_inc[e_counter++] = 1;
更新 2018.3.24
之前的是对CTC原理中动态规划部分的主要解释,今天我们来讲一讲它就是如何应用到RNN中去的。为了方便,我将采用CRNN模型,论文地址。
了解CRNN后知道,CRNN的输出是一个序列y = y1, y2, y3, … yT, 其中yt是一个字母表+空白的概率分布,我们定义π是y的其中一种情况(path),定义一个函数(Sequqnce to Sequence)B,B(π)是产生一个标签(label),比如B(–he–l-l–oo-)是hello,我们假设真实标签是l, 那么在训练的时候,我们首先需要求出输入在进入CTC之后,所产生的输出是l的概率,也就是条件概率。如图所示:
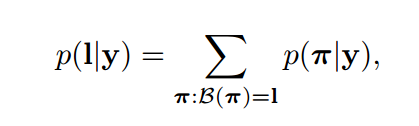
根据这个概率,我们可以采用negative log-likelihood来计算损失函数,从而bp和optimize。这里面,p(π|y) = Π(yt(πt)),如果直接计算p(π|y)当然非常复杂,所以CTC采用了动态规划的思想,也就是我上面介绍的内容。