
Detection is an important part of computer vision. Today I will take a view at the prevailing algorithm in detection areas, named RCNN and it’s extension.
RCNN
RCNN’s meaning is region based CNN. Unlike yolo and yolo9000, RCNN chose the region as the base of it’s predict bounding boxes. Finding that if we just use the location like x, y, then it’s hard to converge, because firsty there maybe exist a couple of objects and then the x, y have difficulty deciding which to approach. secondly, x,y has no limition and can appear in anywhere on the image. So RCNN use prechoosed region and then finetune the bounding boxes, actually compute the scaling and offset. The RCNN’s precess is like this:
- use some methods to generate regions(e.t.c selective search)
- adopt the CNN model to extract the feature.
- put the feature map into the SVM binary classifier.
- put the feature map into the regressor to finetune
The schemetic diagram is below: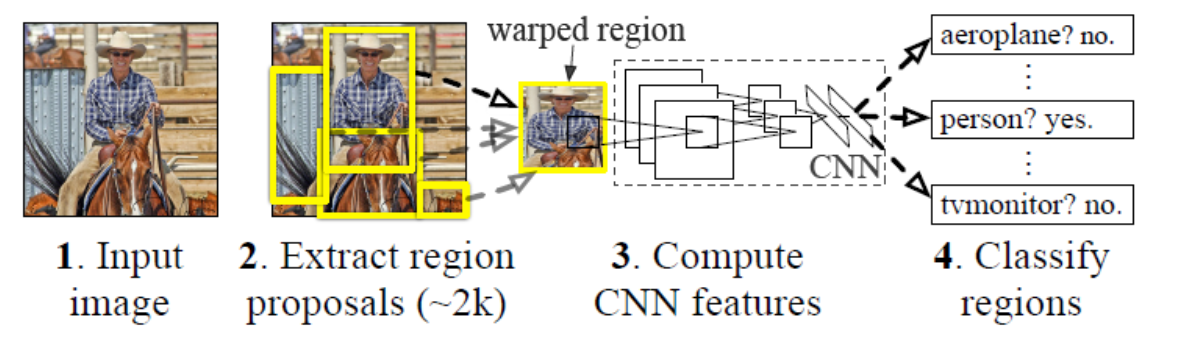
Note that RCNN is puting the every region into the network to train which consume a lot of time. Also note that RCNN had to first wrap resize every region into fixed size because FCN is required fixed-size input. So we will find the image to be a little geometric distortion.
The training detail is: First we resize the image to 227 * 227, then we pretrain the image on the ILVCR(It has 1000 categories). Next we adopt domain-specific fine-tuning on the PASCAL VOC 2007(21 categories, 20 classes and 1 background). When we test, we put the layer of 4096 dimension into the SVM classifier and likewise we put the layer into the regression to compute the scaling and offset.
RCNN is the foundation work of image detection using neural network. It still has a lot of drawbacks which will be solved in the next few algorthims.
SPPnet
SPPnet add a layer called spatial pyramid pooling layer. The pooling layer is like this:
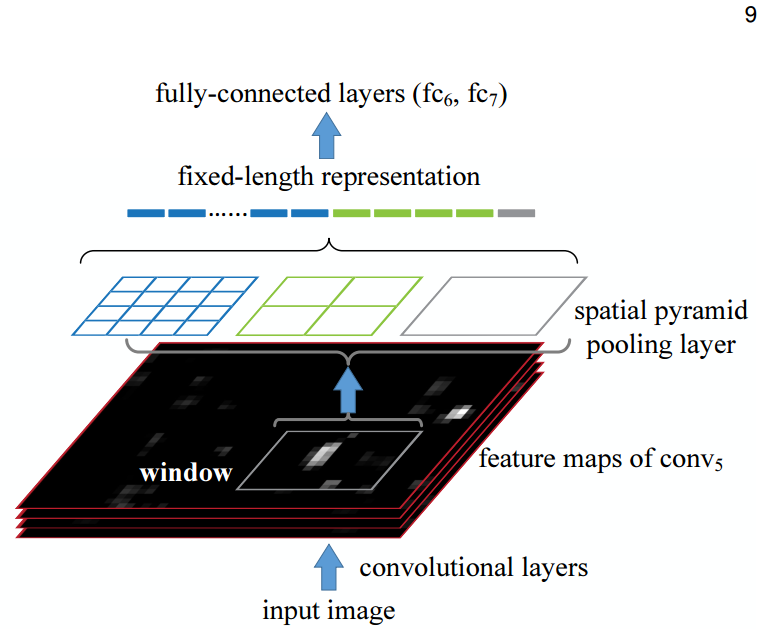
Suppose we assume that the feature map is H W size. Then we want to put the feature map into 4 4 so we need to manually regularize the stride to H/4 W/4 and the kernel size of H/4 W/4. Consequnently, the feature map is resized into 4 4. Likewise, the 2 2 and 1 * 1 feature map is generated. Then we flat and cluster them into one vector and sent it to the fully-connected layers. It plays the role of generate a fix-sized feature map.
There exist quite a few advantages to use this method. Firstly, RCNN use wrapping to resize the region into fix-size feature map which will cause geometric distortion(like below). And this method will avoid that kind of problem. Moreover, we don’t need to put every region into the network any more. We put the whole image into the network instead. We just need to know where the region is. Depending on this change, the running time is dramatically reduced.(below)
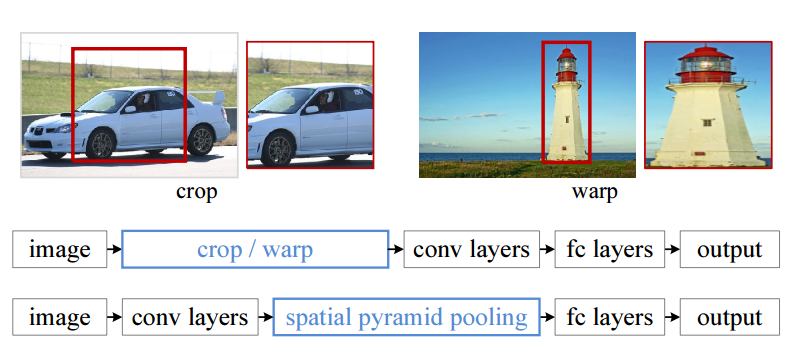
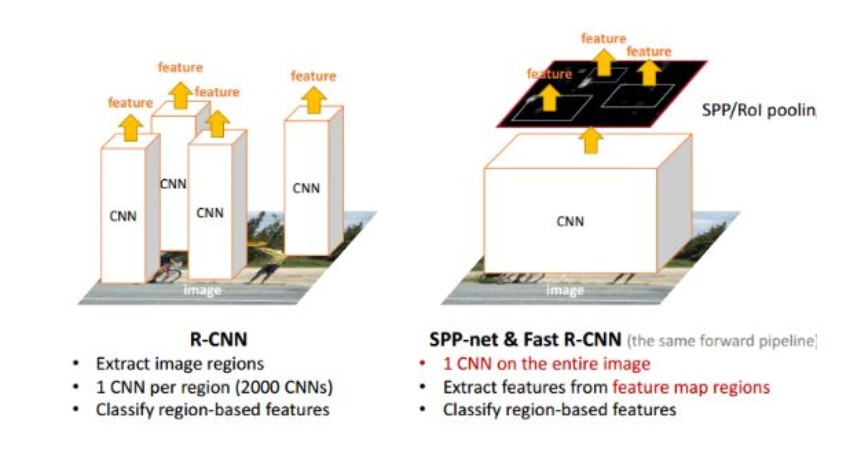
Fast RCNN
We know that RCNN and SPPnet has Multi-stage pipeline —— we need to put the final output into the SVM and then the regressor. Fast RCNN is born to handle the preblem. The trait of Fast RCNN is single-stage and multi-task. The schemetic diagram is below:
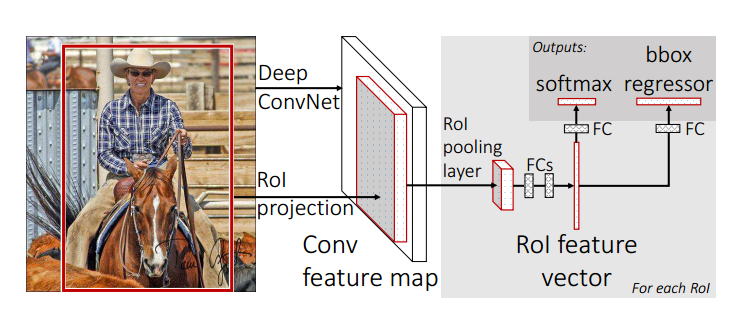
They use softmax to replace SVM because they find softmax is litter better than SVM in this task. We find that all tasks is compressed into one network.
Another change is that they replace the spatial pyramid pooling layer with a ROI pooling layer(ROI : region of interest) which is a simplified version of SPP. They only use one scale like 7 7 instead of 4 4 + 2 * 2 + 1 because they experimented to find that complication brings no improvement.
Faster RCNN
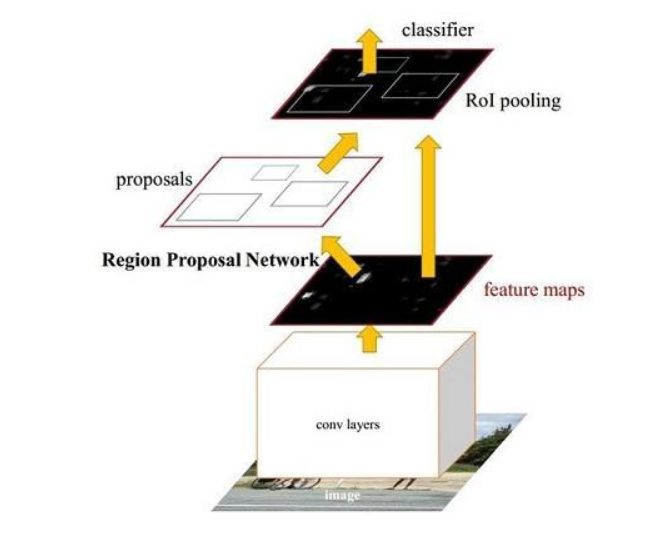
The whole growing histroy we can summarize as a process of group all task into one single network. Faster RCNN contributes to moving the generate regions process to the network where we call it RPN (Region Proposal Network). The overall proceeding is like this:
The detailed schemetic diagram is like this:
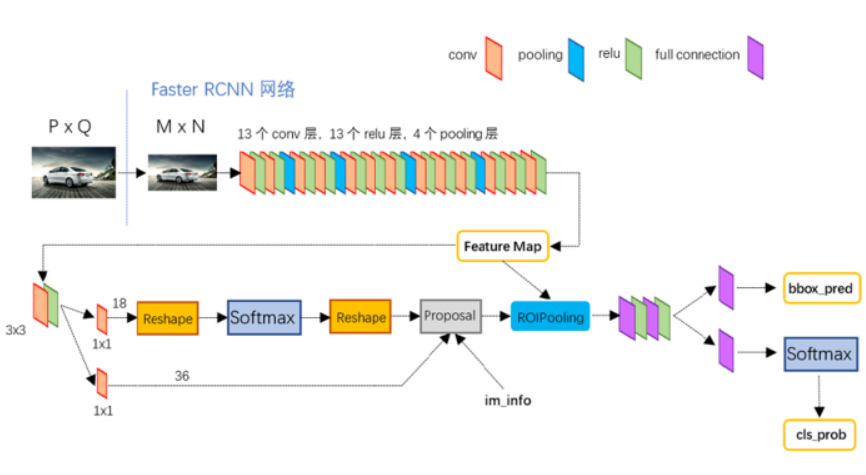
In order to generate appropriate proposals, we need to first define some fix-size and fix-location anchors by ourselves. we need to define different aspect ratio and different size so as to suit different object. The detail is like below:
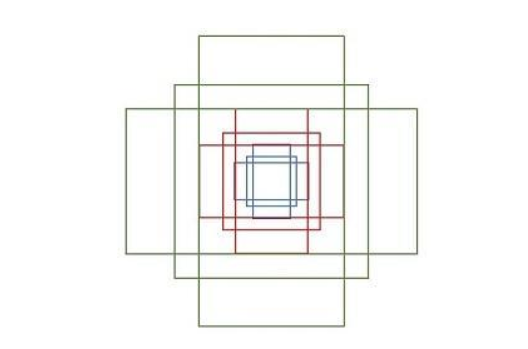
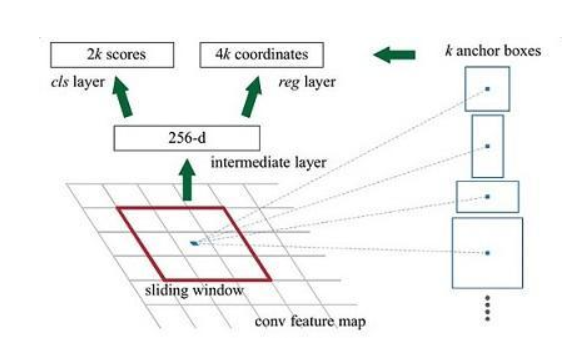
We need to explain some place in the picture 2. As we all know, for one feature map and for one pixel, it has a receptive field. If we project a pixel in the feature map somewhere to the raw image. This will be an area which we call grid ceil. For one grid ceil, we define k anchors. In this paper, we consider k as 9 in default. 2k means that for k anchor, there will be two categories, whether it has a object or not. 4k’s 4 means (x, y, w, h) for every anchor.
Based on the explanation above, we can take a step forward. The detail RPN is like this:
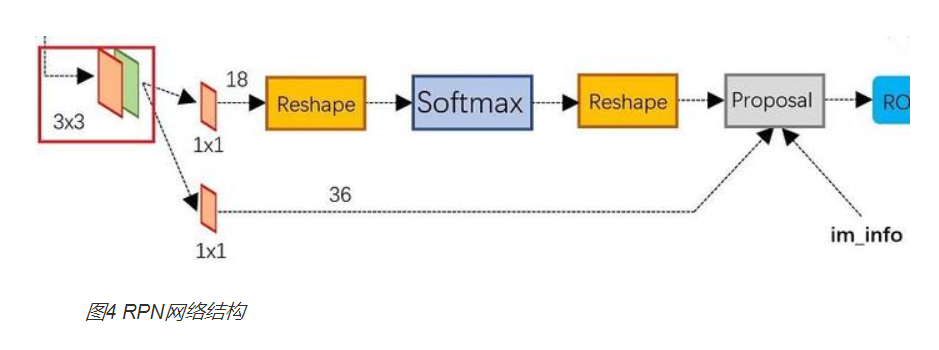
The network above is a classification layer. And the third dimension is eighteen filters which is 2 × 9(k), 36 is the 4 × 9(k). We send all of this into the proposal layer which we include sorting, NMS, and sorting and NMS again(NMS : non maximum supression).
Mask RCNN
The main change to the Mask RCNN is below:
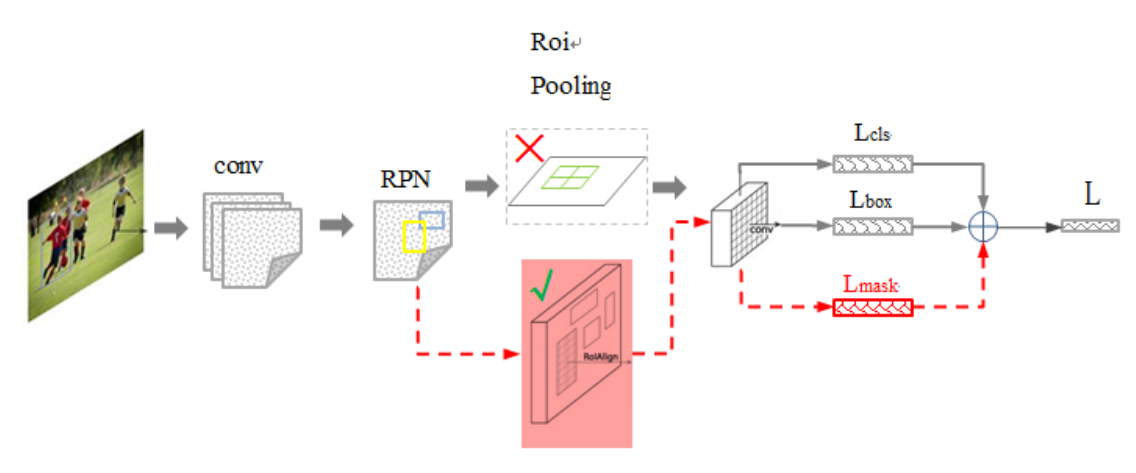
The network add a Lmask task in the final network and replace the ROI pooling with the ROI Align network. The network itself is also improved
on the basis of the some methods called ResNeXt-101 and FPN.
ResNeXt-101 is an updated version of Resnet. The ResNet and ResNeXt-101’s structure is like below:
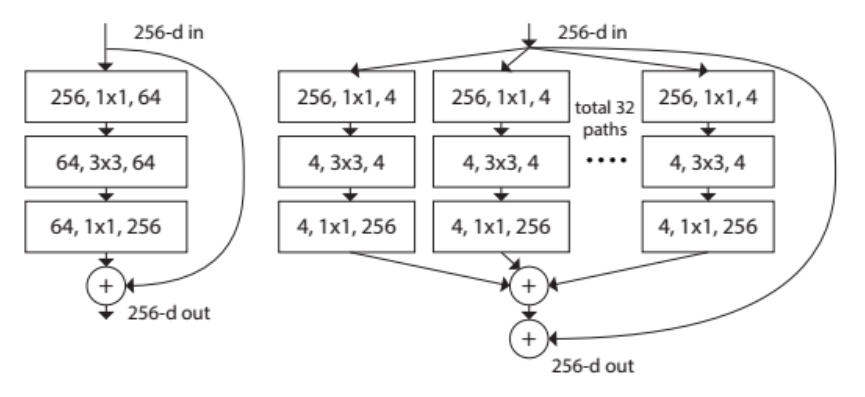
ResNet is a network to solve the draback of deep convolutional network. When the convolutional network is becoming deeper, the accuracy become lower. Because the deeper layer has the responsibility of predict the truth. So we can use the method of boosting tree. For one layer, we only predict the residual of them. For example, we have the input x, and output is F(x), and the truth is T. If we want to compare the F(x) and T, the pressure is huge. But instead we can use F(x) to compare to the T - x, then it’s easier. ResNet is a example of this. ResNeXt-101 is an improvement of it. ResNeXt-101 is inspired by the neurons. As we all know, neural network has many neurons which play the role of learn the different feature independetly. So the ResNet-101 use the method of split-transform-merge. The total 32 parts play the different role.
FPN is born to handle the problem of difficulty of detecting small object. Suppose that a small object is 32 * 32, then if we have a network that has a smaller multiple of 32. Then the last feature map the object only has one pixel. In order to solve the problem, some papers like SSD use the method in the third picture. For the proceeding feature map, each has a predict value. But we know that for every feature map, it has the role of learning different semantics. Like the higher map learn the high semantics and the lower map learn the low semantics. It’s imappropriate to use different feature map to predict the result. So FPN(Feature pyramid network) change it. The lower feature map combine the trait of the higher feature map. But the upsample process has a lot of loss. So we need to use lateral connection —— combine the network before. The detil is as below: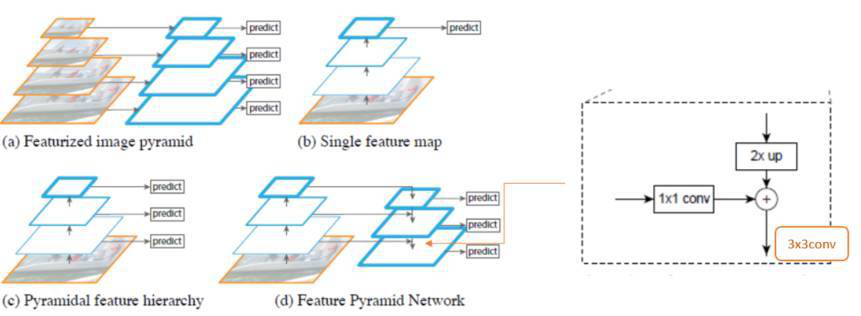
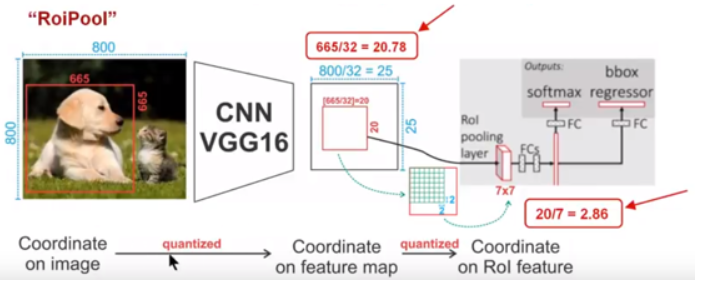
ROI Align solve the issue of misalignment. ROI pooling use the method of neareast neighbor interpolation. Suppose one region is 665 665, then after some steps of maxpooling, with a division of 32, the pixel is floating point which is impossible. Another point, using ROI pooling, if the size is 20 20, you want to the fix-size of 7 * 7. Then the stride is also floating point. if we just rouding, the loss will be huge.(See the picture) So ROI Align use the bilinear interpolation.(Picture below). It’s more scientific to use two dimension to rounding.
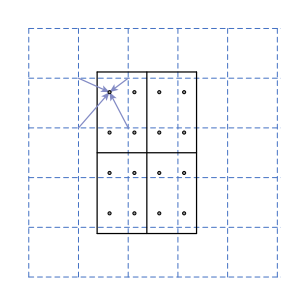
We don’t introduce mask, because it’s the area of semanic segmentation.