
训练深度神经网络的时候经常会出现的问题是在每次训练的时候输入的数据发生一丝微小的改变,会改变之后的所有层,并且层数越深影响越大。也可以说当输入的分布发生变化,网络就不得不再去适应新的数据分布。这会导致一个模型非常难训练出来。一旦训练速率与参数初始化不恰当,模型就不会收敛。这个现象被称之为covariate shift。并且,对于每一个网络层输入的变化都会产生covariate shift 的现象,作者把内部的网络节点输入的变化称之为Internal Covariate Shift. 第二个问题是梯度弥散或者梯度爆炸的问题,当网络深度很深的时候,前面参数的细微变化会导致后面参数更新变化非常大。
解决这个问题通常使用normalizing layer——输入白化(转化为平均值和方差为0,并且去相关花), 并且可以考虑在每个training step以及某一些间隔插入normalizing layer。但是根据论文的举例,使用normalizing layer也就是白化会导致某些参数的更新的效果被抵消,这样的话更新会一直进行下去,但是输出与损失函数并没有发生变化。之所以更新会抵消是因为梯度下降忽略了normalizing layer 参数对其他参数的依赖。也就是梯度流忽略了normalizing layer。如果求梯度的时候考虑normalizing layer,则计算非常的耗时,需要计算协方差矩阵以及白化部分。并且白化并不是处处可微。
有两个方法简化计算,一个是讲每个特征当做是独立随机变量单独进行规范化,这样就不存在协方差矩阵。另一个是在每个mini-batch中计算mini-batch和variance来代替整个数据集的mini-batch和variance.因为对于mini-batch gradient decent,计算整个数据集的mini-batch和variance是不切实际的。
如果仅仅将每一层的输入都进行规范化,那么会改变原先这一层的表达能力,比如本来有两个值,一个在sigmoid函数的线性区域,一个在sigmoid函数的非线性区域,进行规范化后两个值就都作用在了sigmoid函数的线性区域了,原来sigmoid函数的表达能力就没有了。所以加上了一对参数γ和β,来scale和shift规范化的值。
为什么Batch Normalization会解决数据分布的问题以及梯度弥散的问题? 首先看数据分布的问题,一般数据z之间都是互相关的,拿二维的数据进行举例,假设第一次输入的数据都是主要都是在第一象限。
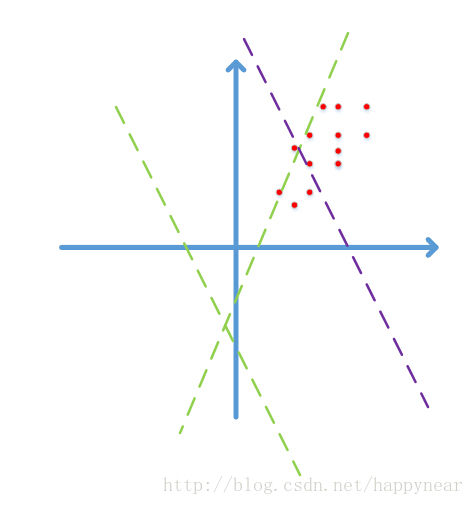
在之后经过每一层的操作之后,数据分布都会发生变化,如果网络足够深的话,后面几层的网络接受的输入分布会与之前的数据分布完全不一样。我们希望数据的分布最好是稳定的。所以我应用Batch normalization。使得每次输出的数据都是在四个象限比较均匀的分布。这样数据就会相对的稳定。
再看解决梯度弥散或者梯度爆炸的问题, 前向传播的时候有:
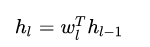
反向传播的时候有:
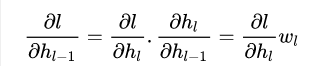
从l层传播到k层则有:
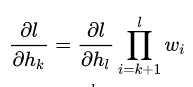
如果w大多小于1, 则会产生极小的梯度,如果w大多大于1则会相反。所以使用Batch normalization来解决这个问题。
首先:
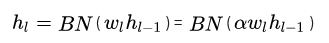
反向传导的时候便有:
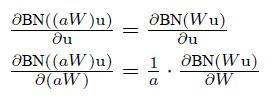
第一个式子指的是:对于无论w多大,对梯度流都有影响。第二个式子指的是,w越大,产生的更新越小,有了这两个特点的保证,就可以保证w的更新更加稳定。
对其本质的思考,训练其实是训练模型的表达能力,区分不同的数据分布,所以,模型会越来越深,表达能力越来越好,但是,模型过深,会产生许多问题,比如数据分布的细微变化,参数细微的变化就会导致后续巨大的变化,导致过拟合,模型的泛化能力很弱,所以,对许多层的数据加入归一化,使得数据分布变化不会那么大,后续模型参数变化也不会过大,但是这样模型的表达能力就变弱了。所以加入γ与β,通过训练γ与β,达到表达能力与泛化能力之间的很好的平衡。
下面是一些检测自己是否理解了Batch Normalization的问题,有兴趣的读者可以看了回忆一下。
问题一:Batchnormalization中说的把每个特征单独做规范化中的每个特征在CNN中是指的什么,batchsize中的m在CNN中指的是什么?
问题二:CNN中做Batchnormalization z = g(BN(Wu))
问题三:为什么要加γ和β的偏置。
问题四:白化的偏导为什么计算量比较大并且某些地方不可微。
问题五:Batchnormalization 放在哪边
问题六:internal covariate shift
问题七:test的时候均值与方差从哪来的。
问题八:如何解决梯度爆炸或梯度消失的。
问题九:如何解决数据分布的变化。