久违的更新~~~,时值暑假,正好把之前没看过的paper仔细的看一遍,也同时为了给自己打下一个更好的基础。我就按照github上的paper的分类精选一个个看下来,paper较多,大约有一百多篇,一个暑假可能看不完,但是我会尽量多看些,并将博客的这个paper系列继续下去。今天讨论的主要是imageNet的演变过程。
AlexNet
AlexNet算是deep learning的重大突破,由于它,deep learning开始被广泛使用。
开始,我们需要知道ImageNet是什么,ImageNet是一个超过1500万已标注的高精度图片,包含有22000个种类(当时的数据),从2010年开始,举办方举办了一个年度的竞赛叫ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)。其中ILSVRC2010的测试数据集是可以利用的,因此,本paper的大部分试验都在这个数据集上做的。
思想
文章首先提出,现实中的问题不像ImageNet上的数据集一样如此特定和单一,因此,对于现实中的问题,需要的模型应该有足够的复杂包容度。而卷积神经网络恰恰有足够的容量(learning capacity)和容量控制能力(随意的控制深度和宽度)。
由于ImageNet包含不同精度的图片,而我们的神经网络要求固定的输入维度。因此图片采用下采样到256×256。下采样的方法是先rescale将宽变为256,再在中心裁剪出256×256的图像。
激活函数方面paper使用的是RELU,对比于tanh以及sigmoid这些linear activations. RELU这样的non-linear activations 能够生成non-saturating neurons(处理之后没有被挤压到一个特定区间的值),在训练梯度下降的时间方面,non-linear activation更快。
在使用GPU方面,由于当时GPU的限制,论文中使用了两个GPU,现在自然不再需要。
normalization方面,采用Local Response Normalization,增强泛化。
pooling方面,采用overlap pooling,也就是sizeX > stride从而导致相邻池化窗口有重叠。
减少过拟合方面,采用了两种方法。一种是通过数据增强来人为的增加数据量。一种是dropout。数据增强是将原有的图片提取随机的224 * 224的部分(patches)以及它的水平投影(horizontal reflection), 取四个角落以及中间的部分以及它们的水平投影也就是有10个部分(patches)。还有一种数据增强则是改变训练图片RGB channels的强度。特别的,使用PCA(Principal Component Analysis)来处理ImageNet训练集中一系列的RGB元素值。PCA主要通过将原始数据变换为一组各维度线性无关的表示,可用于提取数据主要特征分量,常用于高维数据的降维。有关PCA的数学原理见PCA的数学原理,
第二种方法是使用Dropout的时候,采用随机dropout。
训练的细节:
- batchsize 128
- momentum 0.9
- weight decay 0.0005
对于权重w的更新规则如下图所示: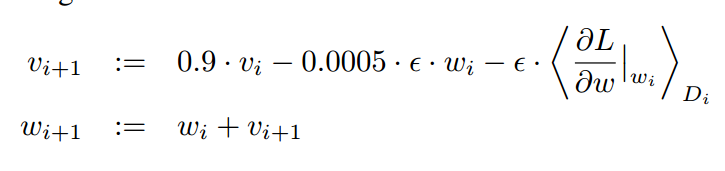
其中v是momentum的变量,i是循环的下标,还有一个不会读的是学习速率。
初始化权重的时候使用一个以0为平均值的高斯分布,其中标准偏差为0.01,对第二层第四层第五层的卷积层以及全连接层的神经元初始化偏置为1。剩下的偏置为0。
训练的速率对于所有的层都是一样。调整采用的是启发法,初始的速率设置为0.01,每当validation error不再下降的时候,速率就除以10,直到执行这个操作3次以后为止。
总的架构下图所示。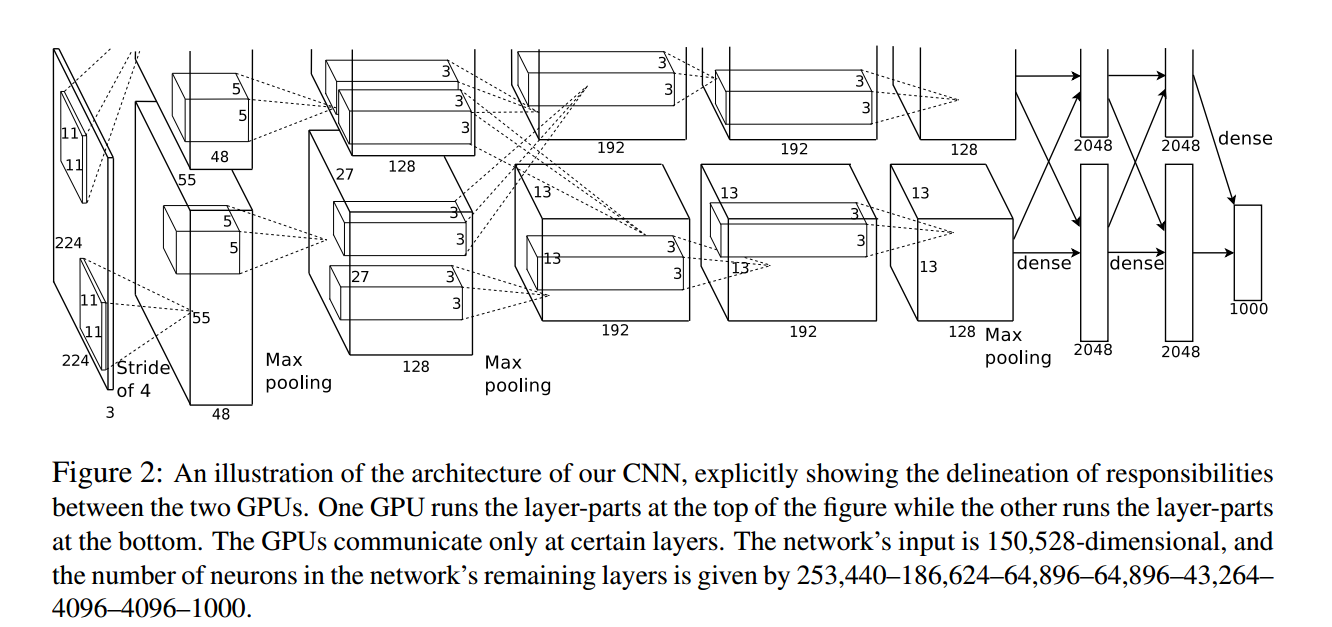
VggNet
vggNet总结了在AlexNet出现之后近些年的一些成果,是其集大成者,一方面的改进是使用更小的窗口(receptive window)和更小的步长(stride)。另外一个方面的改进是训练和测试网络分开,训练采用整张图片以及多尺度的图片。而本片论文提高方向则是增加深度,由于使用的比较小的窗口(3 × 3),参数量较小,因此增加深度是可行的。
architecture
输入: 224 × 224
预处理 : subtract the mean of the RGB value (training set, each pixel)
总体架构如下图所示: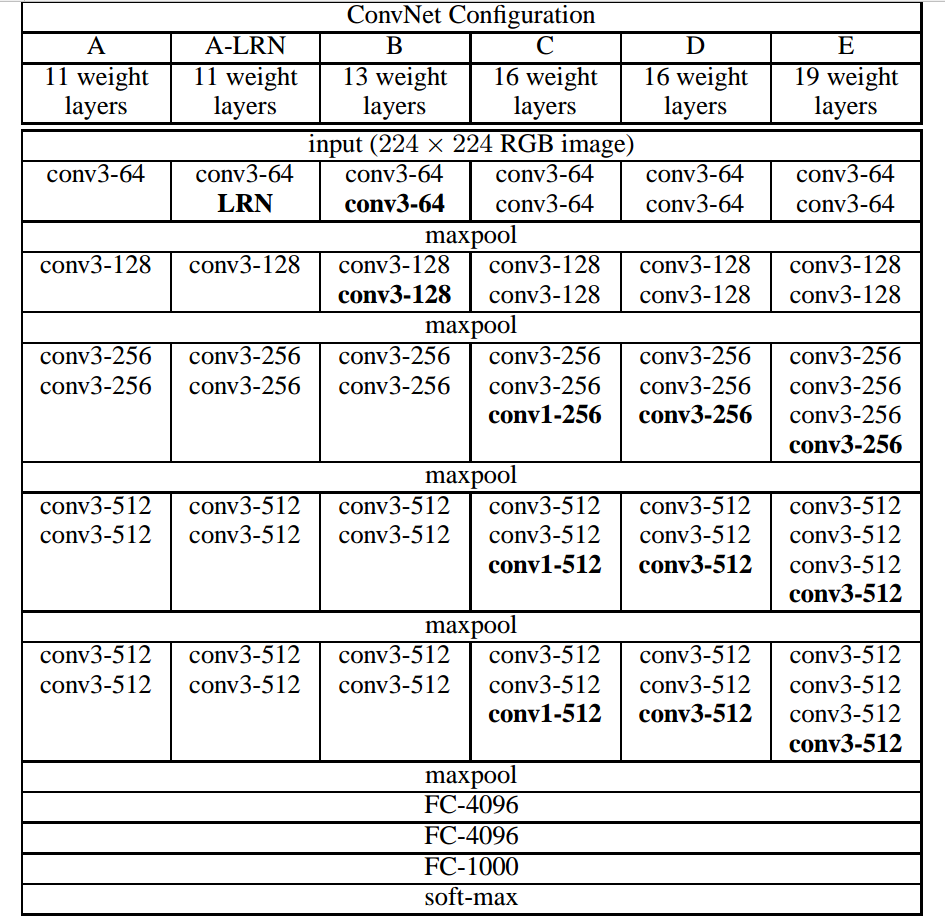
滤波器
使用三个3 × 3的小窗口来代替1一个7 × 7的窗口的原因:
- 有三个non-linear rectifiction layer而不是一个可以让决策函数更具有辨别能力(make the decision function more discriminative)
- 参数量:假设有C个channel,则前一个的参数量为3 × (3 × 3 × C),后一个的参数量则为7 × 7 × C。
1 × 1 卷积层的加入
增加decision function的非线性性,同时也能够避免影响卷积层的感受野。尽管卷积层本身是线性映射,但是由于还增加了RELU层,所以引进了非线性性。
专注于跨通道的特征组合,不考虑局部信息组合。
对feature map的channel级别降维或者升维。
池化层
一般常见的网络的结构大多为INPUT -> [[CONV -> RELU]×N -> POOL?]×M -> [FC -> RELU]×K -> FC,vgg net的池化层不同于Alex Net采用的3 × 3 stride为2的maxpooling,而是采用的2 × 2 stride为2的maxpooling。池化层做的事情是根据对应的max或average的方式进行特征筛选。小的kernel带来的是更细节的信息捕获。
特征图
网络在随层数递增的过程中,通过池化也逐渐忽略局部信息,池化操作使得宽高每一次都变为变为一半,而深度每次增加一倍。信息分散到channel层级上。特征图从channel从512开始进入全连接层,全连接层与卷积层相比更考虑全局信息,三个全连接是为了捕捉特征映射来去之间的细微变化。
layer pattern
vgg net 有两种layer pattern,第二种([conv-relu]-[conv-relu]-[conv-relu]-pool)比第一种([conv-relu]-[conv-relu]-pool) 多了一个[conv-relu],我的理解是
- 开始时feature map的local特征信息更加多一些,之后通过增加conv filter的方式扩大channel的数目,在一个layer pattern的中层,channel数已经足够,当再想提取lacal的信息的时候,就加一层[conv - relu]的形式来压榨提炼特征。类似于使用非线性变换对已有特征进行变换,从而产生更多的特征。
- 多出的conv对网络中层进一步进行学习和控制保证特征信息不漂移到channel级别上。
- conv本身更加注重单张feature map的局部信息,尽量去平衡channel(depth)级别与local级别(width, height),控制特征信息不要过于向channel级别偏移。
关于layer pattern
- 串联和串联中带有并联的网络架构。GoogleNet引入inception模块,ResNet引入Residual Block。串联带有一些并联同类操作但不同参数的模块在特征提取上更好(做特征工程)
- 用在ImageNet上预训练的模型。
training detail
在训练的细节方面,几乎与AlexNet相同,额外的bathsize选择的是256。在初始化的方面,需要非常小心,首先对于上图中的configuration A,采用随机初始化进行训练,然后对于更深的模型,将前四个卷积层以及最后三层的全连接层使用A的参数,中间的层采用随机初始化。
全连接层的随机初始化:
- FC4096-ReLU6-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
- FC4096-ReLU7-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
- FC1000(最后接SoftMax1000分类),FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
实际并非采用的Alex net的std = 0.1, bias = 0。
在training image size方面,假设S是训练图片的宽,crop size固定为224 × 224。single-scale的S是固定的一个值,而Multi-scale则是S是一个范围,也就是将图片rescale到S(不同的值,通常是一个范围),然后再用固定的尺寸crop。test detail
参考overfeat,测试的时候将最后的全连接层该为卷积层,从而可以处理任意分辨率的图片,无需对原图进行resize。但是若原图大于resize之后的图片,那么将最后的s × s的feature map进行average,最终交给softmax的还是1 × 1的feature map。
GoogleNet
Google Inception Net 首次出现在ILSVRC 2014的比赛中,获得了第一。被称为Inception V1, top-5错误率6.67%。只有AlexNet的一半不到,它有22层深。计算量有15亿次浮点运算,500万的参数量。降低参数量的好处:
- 参数越多模型越大,所需要的数据量越大。
- 耗费的计算资源少。
参数少的原因:
- 去除最后的全连接层,全连接层占据了AlexNet或VGG Net的90%的参数量。采用了全局平均池化层(将图片尺寸1 × 1)来取代。这样模型训练更快并且减轻了过拟合。
- InceptionModule提高了参数的利用效率。
一般对于卷积层来说,要想提升表达能力,主要依靠增加输出通道数,但副作用是计算量增大和过拟合。每一个输出通道对应一个滤波器,同一个滤波器共享参数,只能提取一类特征,一个输出通道只能做一个特征处理。Inception Net允许在输出通道之前组合信息,因此效果明显。
Inception module
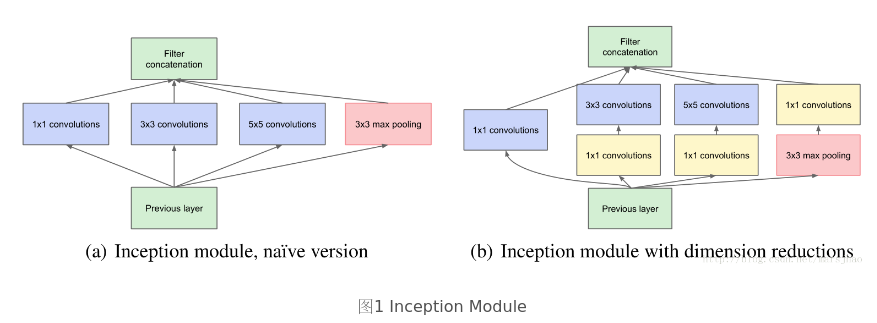
首先讨论稀疏结构(sparse data structures),Inception Net的目标是找到最优的稀疏结构单元(Inception module), 基于Hebbian原理以及论文Provable Bounds for Learning Some Deep Representation的观点可以得到:如果数据集的概率分布可以被一个很大很稀疏的神经网络所表达,那么构筑这个网络的最佳方法是逐层构筑网络:将上一层高度相关的节点聚类,并将聚类出的每一个小簇连接到一起。
卷积操作就是将相关性高的一簇神经元节点连接在一起,1 × 1的卷积可以很自然的把这些相关性高的。同一个空间位置但是不是同一个通道的特征连接在一起。适当的使用一些大尺寸的kernel也可以添加多样性。Inception Module通过4个分支中不同尺寸的1 × 1, 3 × 3, 5 × 5等小型卷积将相关性很高的节点连接在了一起,就完成了其设计初衷,构建出了很高效的符合Hebbian原理的稀疏结构。
在Inception Module中,通常1 × 1卷积的比例(输出通道数占比)最高,3 × 3卷积和5 × 5卷积稍低。而在整个网络中,会有多个堆叠的Inception Module,我们希望靠后的InceptionModule可以捕捉更高阶的抽象特征,因此靠后的Inception Module的卷积的空间集中度应该逐渐降低,这样可以捕获更大面积的特征。因此,越靠后的InceptionModule中,3*3和5 × 5这两个大面积的卷积核的占比(输出通道数)应该更多。
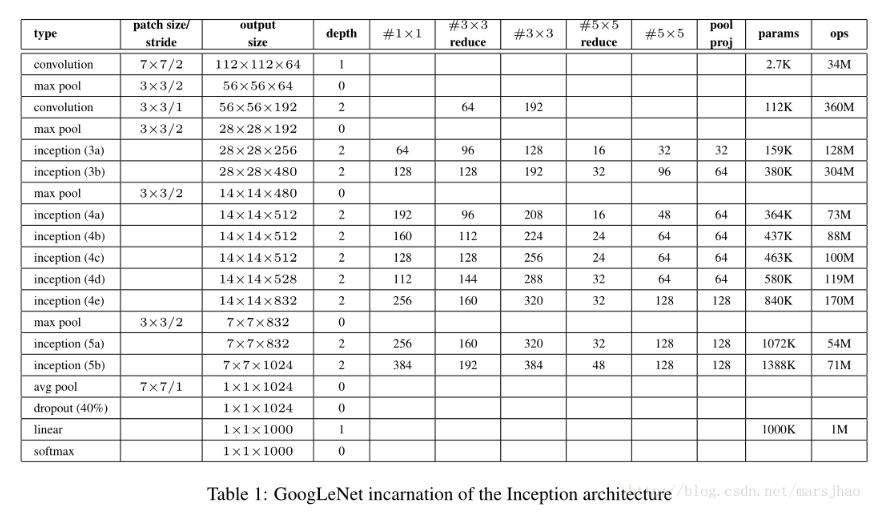
详细的架构如下图所示。
Inception V2
模仿VGG Net,用两个3 × 3的卷积代替5 × 5的卷积(降低参数量,减少过拟合),并且使用了batchnormalization。
Inception V3
两方面的改造:
引入了Factorization into smallconvolutions的思想,将一个较大的二维卷积拆成两个较小的一维卷积。将 7 × 7卷积拆成1 × 7 和 7 × 1卷积,将3 × 3卷积拆成 1 × 3 和 3 × 1卷积。节约了大量的参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力。这种非对称的卷积结构拆分,其结果比拆为几个相同的小卷积核效果更明显,可以处理更多,更丰富的空间特征,增加特征多样性。
在分支之中使用分支。
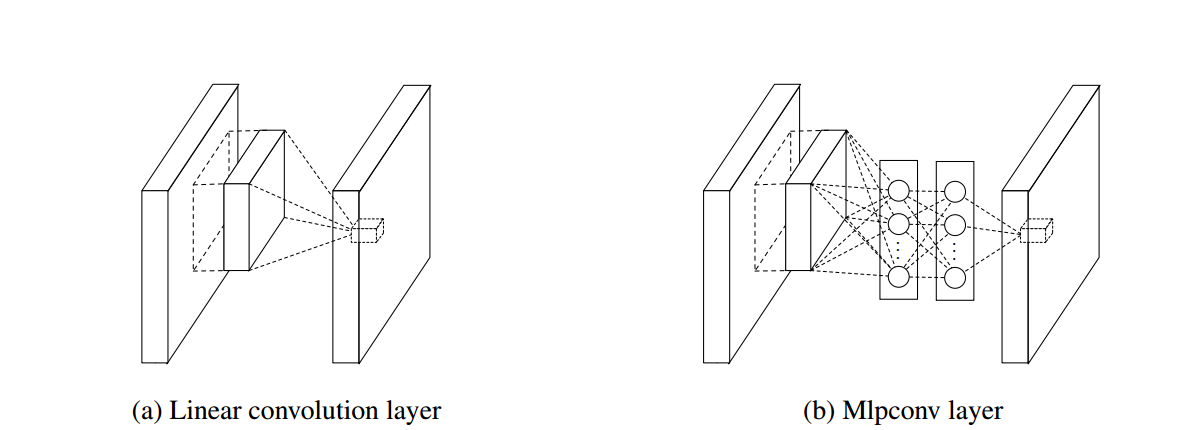
Network in network
Network in network就是指在整个神经网络中蕴含有小的网络(micro network),从而更好的在感受野里面提取数据,在本Paper中,小的网络是一个多层感知机。可以把这样一个小的网络看成一个kernel在图片上滑动。由于网络模型的提升,在分类层我们不再使用全连接网络而是使用global average pooling。原因是减少过拟合并且不像全连接是一个黑箱子,有可解释性。
必要性:作者定义CNN的一个convolution filter是一个泛用线性模型(GLM),他认为GLM对数据的抽象化是低级的(抽象的概念是对于同一个概念的不同变种,它的特征是不变的),GLM默认潜在概念是线性可分的,而实际上,同一个概念的数据都在非线性流形上,因此捕获这些概念的表达是输入的非线性函数。
作者将自己的结构称为mlpconv——将input的local patches映射到s输出的特征向量通过名为多层感知机(几个全连接层和非线性的激活函数)的东西。
MLP Convolution Layers
mlpconv的结构如下图所示:
整个网络的架构如下图所示:
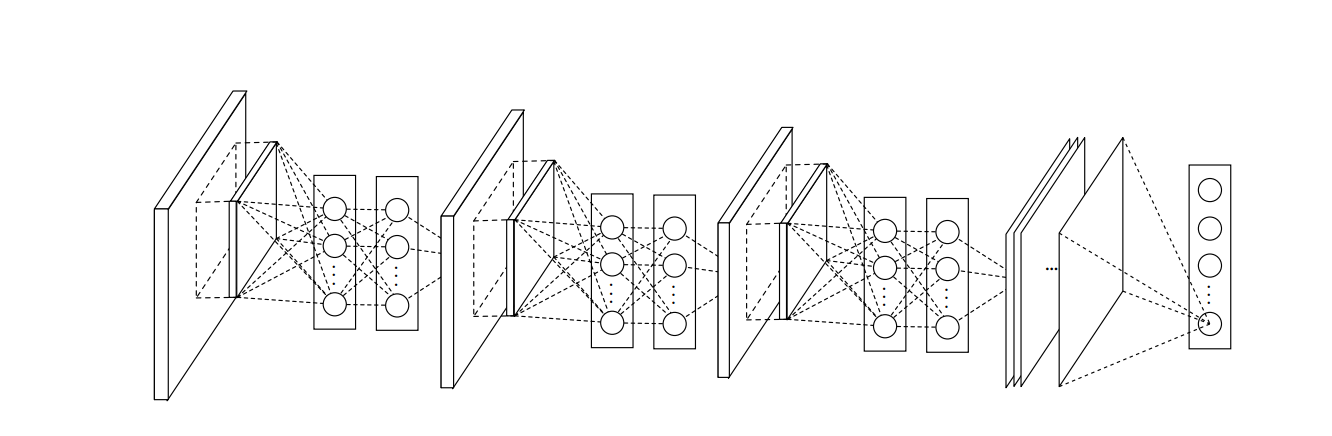
Global Average Pooling
FCN(Fully Convolutional Networks)
key insight: 输入任意,输出为相应大小。
名词解释: dense prediction : the task of predict the labels of every pixel in the image.
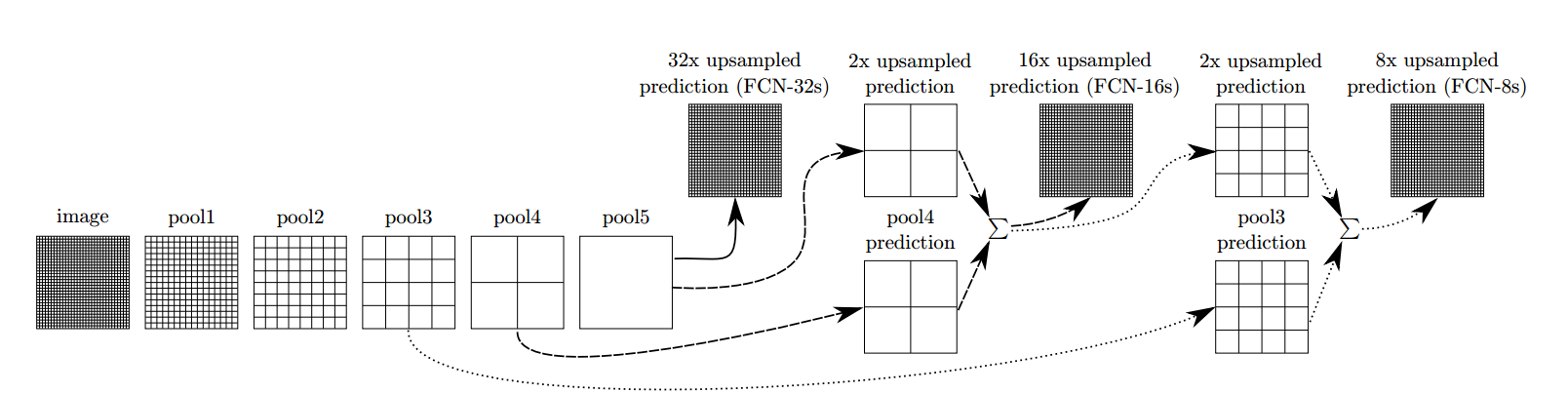
典型的网络,都有全连接层导致整个网络的输入必须是固定尺寸,但是,我们实际上可以把全连接层看做是对整张图片进行卷积。由于使用全连接将图片本身的空间信息破坏了,而卷积网络则是有翻译不变性,输出始终与输入的位置相关。因此将网络最后的全连接层该为全卷积层。结构如下图所示:

经过多次卷积之后,得到的图像越来越小,FCN需要得到每一个像素的类别,采取上采样,经过5次卷积(pooling)之后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。
上采样是通过反卷积(deconvolution)实现,对第5层的输出(32倍放大)反卷积到原图大小,得到的结果还是不够精确,一些细节无法恢复。于是Jonathan将第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。下图是这个卷积和反卷积上采样的过程: