
现有的detection普遍存在的困难是如何解决图片中物体大小变化过大的问题,在有些图片中,物体占了图片的70%~80%,有些则只占了图片的0.01%~0.25%, 单个feature map是很难预测所有的物体因为它的神经元的感受野是有限制的。尤其是小物体,是很难去检测和分类的,因为它们包含很少的信息,容易被当做背景,且对定位的要求较高。具体而言,一方面,网络越深,深层的神经元的感受野很大,stride通常也可以达到32 × 32,导致小物体会被直接忽略;另一方面,对于使用Anchor思想的detection方法,小物体即使在anchor里面,也会因为IoU过小而被忽略。下面,就介绍现在主流的集中缓解Scale Variance的方法。
Image Pyramid
如下图所示:
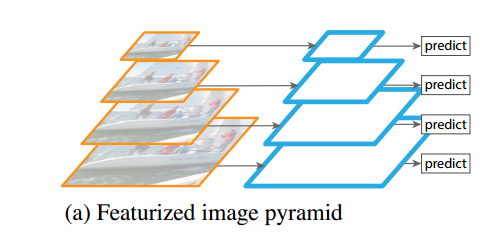
image pyramid大多都不会在训练的时候使用,因为非常消耗计算资源,一般会在测试的时候使用(参考Fast RCNN, sppNet),但是这样的话,就会导致测试和训练的不连续性。因此,这种方式的image pyramid现在已经很少了。
新提出的Scale Normalization for Image Pyramid采取的另外一种思想,首先这篇paper叙述了两个实验,第一个实验是分类实验,通过控制变量说明了
- 如果训练样本和测试样本的分辨率(resolution)相差太大,performance必然下降。
- 对于小物体,如果改造网络结构,将在imageNet上预训练好的模型conv该为3 × 3,stride 改为1的话,最后测试的performance勉强可以。但是需要额外修改网络,很麻烦。
- 不改变网络结构,先在高精度的imageNet上预训练,然后将小物体unsample成低分辨率的图片, 在上面finetune。这个的performance最好。
这个实验充分说明了upsample的好处。紧接着的第二个实验,首先有两批不同精度的图片,800 × 1400和1400 × 2000。对两批图片都进行训练,按照理论,高精度的图片,对于小物体的检测应该更好,实际是对于适当scale范围的物体有很好的检测效果,但是对于很小的物体以及很大的物体效果则下降了。注意,这里图片无论大小,都包含了不同scale的物体。根据这个推断,原因应该是对于CNN而言,其本身就不具备scale invariance即使数据充足,包含不同scale的物体,CNN也很难学到不同scale,CNN能检测不同scale的假象,更多是由于CNN强行用capacity来memorize不同scale的物体,这导致大大的浪费了capacity。该Paper提出的是将scale的范围控制在一个比较合理的范围之内,这样就能比较好的检测出来。但是,如果直接把超过某一个scale范围的物体直接忽略掉,实验的结果是更差,原因是失去了一部分语义特征。因此,下面就是该paper提出的模型Scale Normalization。
Scale Normalization
Scale Normalization的示意图如下图所示:
Scale Normalization的运行机制比较简单,训练的时候,只回传大小在预定范围内的proposal的graident,忽略掉过大或者过小的proposal,在测试中,建立大小不同的image Pyramid,在每张图上都运行这样一个detector,只保留大小在指定范围内的输出结果,最终一起nms。
default reference boxes
许多模型使用一系列的不同大小和长宽比的default boxes来覆盖不同的物体。如SSD(下一点会说明), yolo9000, faster RCNN, R-FCN等。 RCNN系列在之前的博文里面已经说明过,其使用default boxes的思想参考之前即可。
multiple convolutional layer used for prediction
另外一种想法是使用不同层次的feature map来检测不同scale的物体,比如SSD(Single Shot MultiBox Detector)。
SSD
SSD的结构如下图所示:
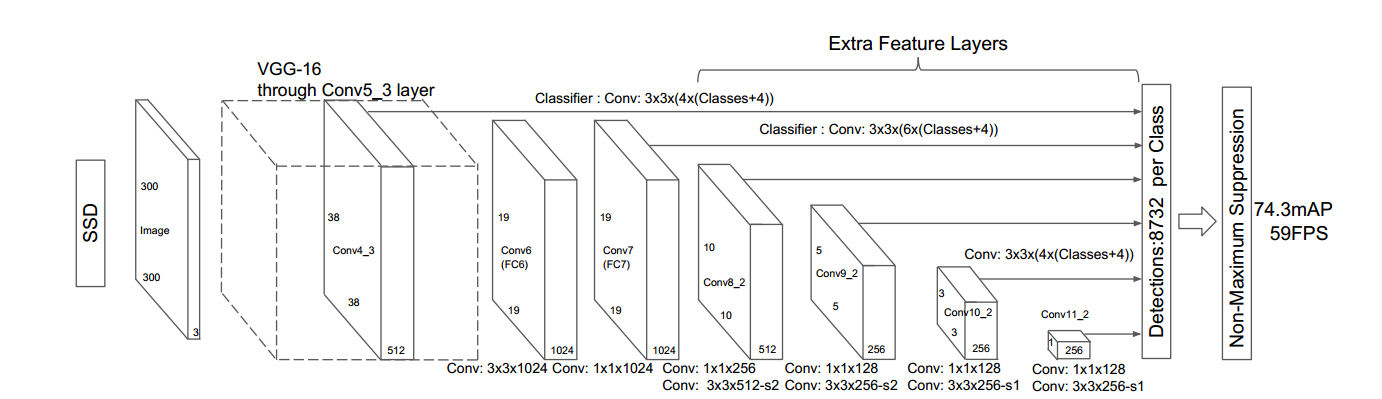
它的总体思想是开始的时候使用一个用于图像分类的base network(vgg 16),然后在后面添加卷积层,并且卷积层的size逐级递减。最后将不同底层和高层的layer综合起来进行预测。
以下说明具体实现的手段。
SSD与一般的region proposals + pooling不同的是,SSD中的bounding box是事先定义好的,固定且默认的。bounding box是在不同的feature map上面的每一个点所对应的receptive field中的不同大小,不同长宽比(aspect ratio)的box,因此是预先定义的,固定的。所要做的是将ground truth去对应这些事先定义好的bounding box。
如下图所示,大的狗的ground truth对应于4 × 4的feature map中的某一个bounding box,而小的ground truth则对应于8 × 8的feature map中的一个bouding box。其余的box则看成负样本。参考图上的信息,我们可以知道,feature map的第三个dimension为4 × P(P个种类,以及(x, y, w, h))。
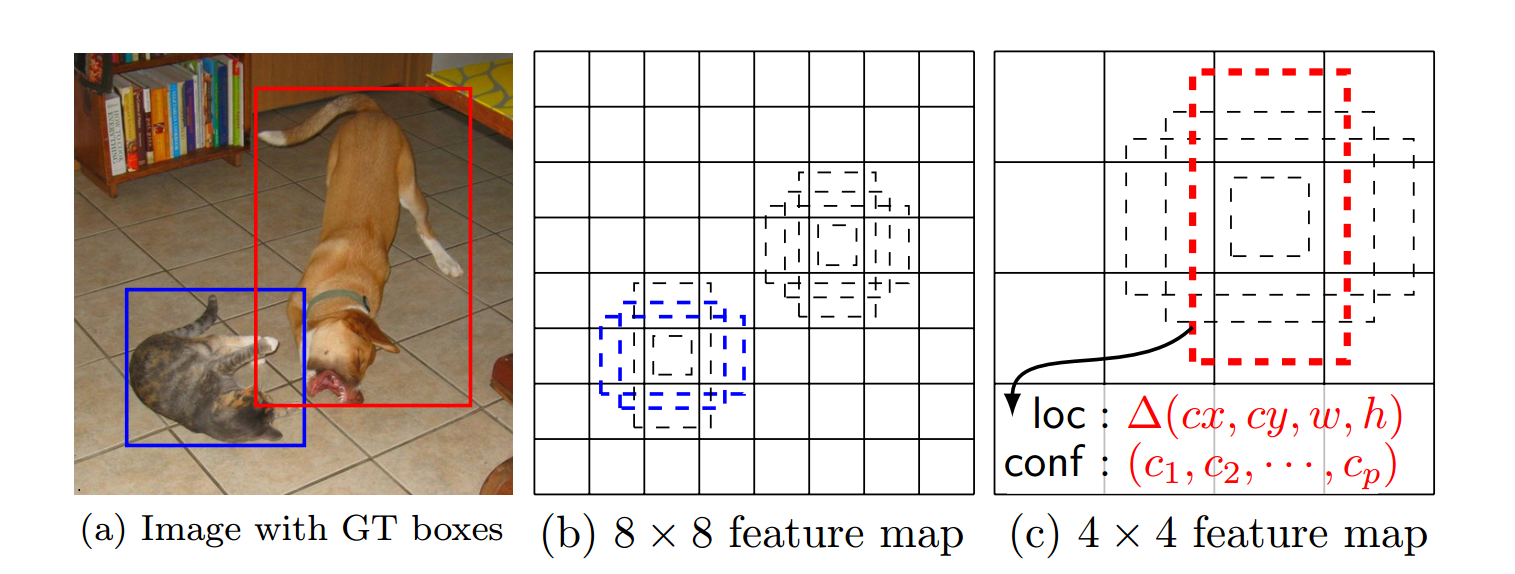
开始的时候,使用best jaccard overlap来匹配ground truth box和default box。设置一个阙值,大于0.5则意味这匹配。
loss函数如下所示
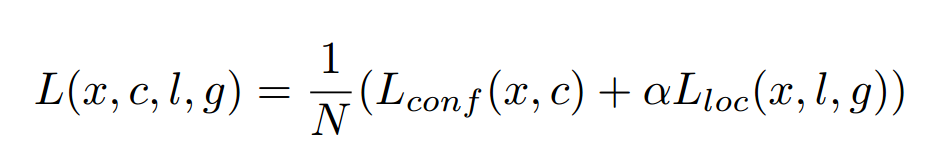
N为与ground truth box相匹配的default box的个数。x为某一个default box与其中一个ground truth box是否匹配,匹配为1,不匹配为0。loc意为Smooth L1 Loss,是predict box(l)与ground truth box(g)之间的函数。conf则是Softmax loss。
Dilated Convolution(astrous convolution)
空洞卷积的使用大大的增加了感受野,但是,其实增加了感受野,对scale variance的问题的解决是没有帮助。因为scale variance产生的原因说到底就是CNN的结构固定,每一层的感受野是固定大小的,无法泛化不同大小的物体。因此,一种解决的方法是让物体的scale相差不大,这也就是第一种方法所采取的策略;另外一种,也就是现在马上要讲到的,让CNN自己学习到灵活变化的感受野。提出的方法是Deformable Convolutional Network。不过,了解它之前,我们需要看一下R-FCN作为基础。
R-FCN
R-RCN的结构图如下所示:
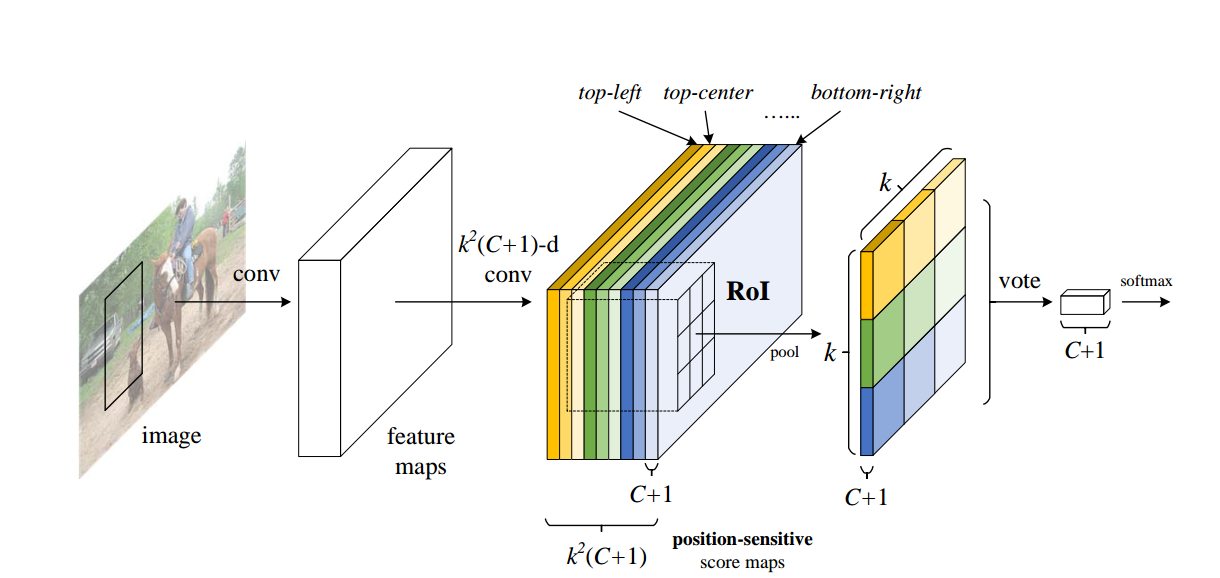
其使用的主要思想是position-sensitive score map。
首先,R-FCN会在共享卷积层后面加上一个一个卷积层,channels为K^2 × (C + 1)。K指的是对于一个ROI,将该ROI划分为K × K个bin,分别代表每一个方位,比如左上就代表该物体的左上位置。因此,C + 1指的就是C个种类加1个背景,而K^2则是指每个channel代表一个方位。如果该ROI中含有某个c种类的物体,那么按照上图所示,则是在每个方位的channel块里面找到该种类的channel,这个channel中对应位置的ROI的对应方位的bin中要有高相应值。score map就是把这个类里面相应方位的bin都取出来,组合在一起,投票决定是否真的包含这个类的物体。那么如何投票决定呢?
文中采用的是如下公式:
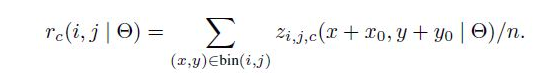
相当于显示平均池化,再将所有的bin求一个总和,然后对所有的类使用softmax函数即可得到各个类别的概率。
Deformable Convolutional Network
deformable convolutional network 参考了R-FCN的部分思想,同时又借鉴了dilated convolution的思想,它的核心思想是训练出一些offset,让原先固定的kernel(如3 × 3, dilation = 1)变的灵活(根据offset进行相应的缩放)。情形如图所示:
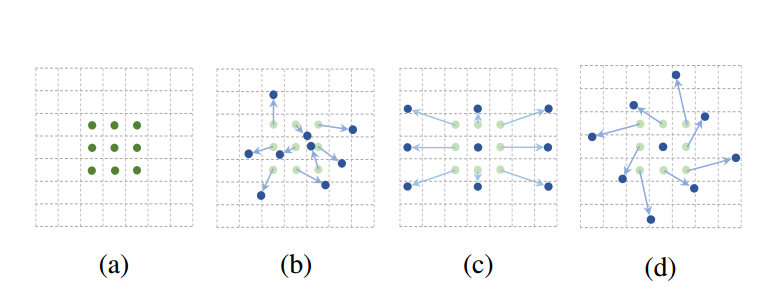
缩放之后的结果很可能不再任何节点上,这个时候就采用双线性差值的方法进行求解。具体的结构如下图所示:
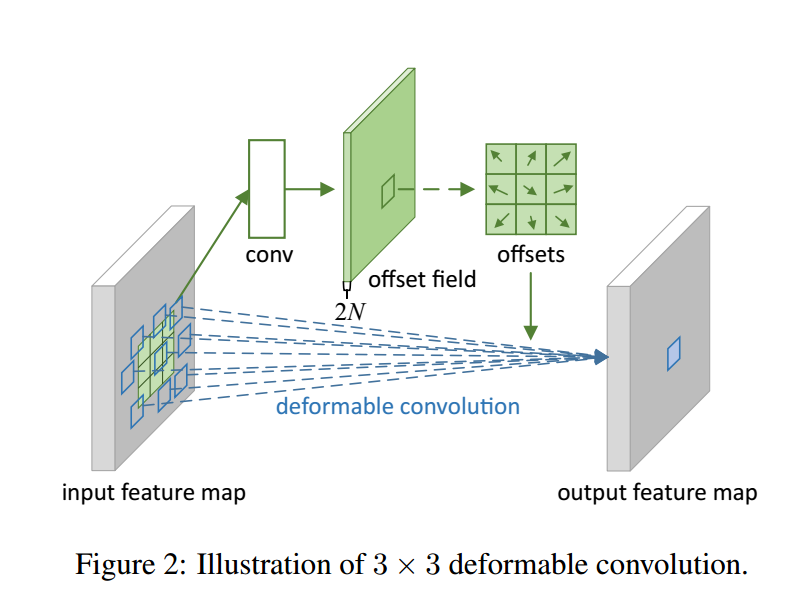
想要训练offset的话就需要额外增加卷积层。就是上图中上方的部分,首先讲之前的卷积层通过额外的一层卷积获得大小不变,而channel变为2N的卷积层,N为卷积核所含节点的个数(比如3 × 3的卷积核N就为9),offset为2D,因此总的为2N。接着在对应channel的对应位置获取的值,综合起来,就是上图中的offset,然后将其应用到之后的卷积之中去。这是Deformable Convolutional Network使用的其中一个方法。
另外,由于模型的改进是基于其他state-of-art的模型的。对于faster-RCNN而言,其ROI-pooling要做到改进的话,也用到了deformable RoI pooling,如下图所示:
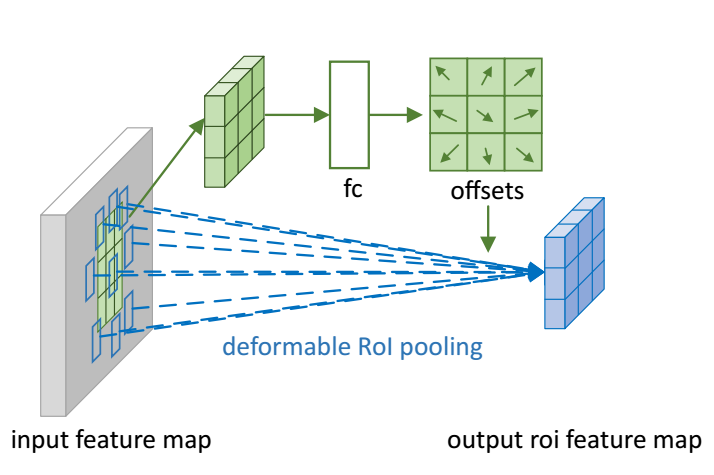
操作与之前类似,经过fc之后产生的offset乘以ROI的width或height以及γ (default0.1)算出偏移量,将对应的地方(偏移量非整数使用非线性插值)取出来构成output roi feature map。
但是,如果模型是基于R-FCN的话,ROI-pooling层就变为了 deformable PS RoI pooling(PS:position-sensitive),如下图所示:
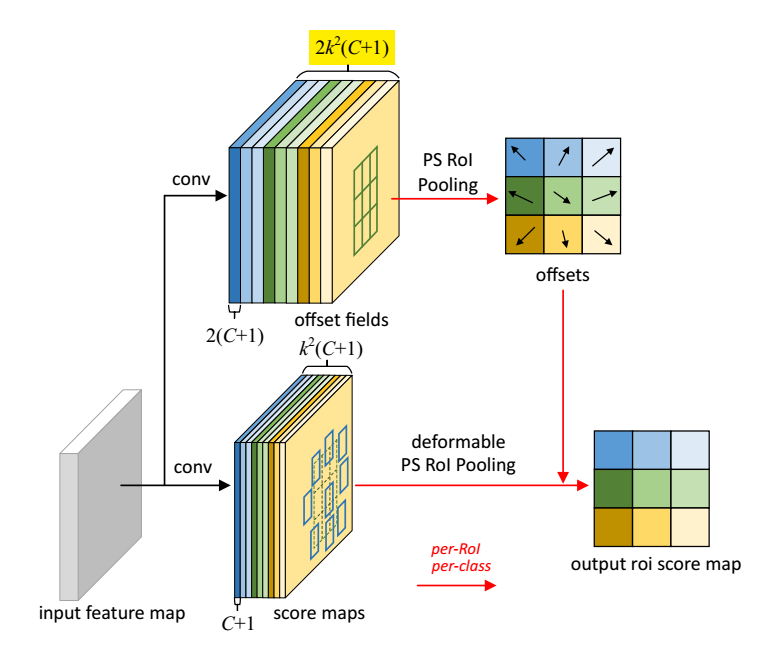
理解了deformable RoI pooling之后以及看了R-FCN之后,这个改进就非常的简单了,实际上就是将原来固定的bin做了偏移而已,这里不再详述。
总结
以上就是目前应用比较广的解决scale-variance的方法,第二种和第三种是比较早期的思想,第一种和第四种则是在分析了CNN的内在之后找到了的方法。